Apache Spark is a free, open-source, general-purpose framework for clustered computing. It is specially designed for speed and is used in machine learning to stream processing to complex SQL queries. It is capable of analyzing large datasets across multiple computers and processes the data in parallel. Apache Spark provides APIs for multiple programming languages including Python, R, and Scala. It also supports higher-level tools including GraphX, Spark SQL, MLlib, and more.
In this post, we will show you how to install and configure Apache Spark on Debian 10.
Step 1 – Install Java
Before starting, you will need to install Java to run Apache Spark. You can install it using the following commands:
apt-get update -y
apt-get install default-jdk -y
After installing Java, verify the Java installation using the following command:
java --version
You should see the following output:
openjdk 11.0.11 2021-04-20 OpenJDK Runtime Environment (build 11.0.11+9-post-Debian-1deb10u1) OpenJDK 64-Bit Server VM (build 11.0.11+9-post-Debian-1deb10u1, mixed mode, sharing)
Step 2 – Install Scala
You will also need to install Scala to run Apache Spark. You can install it using the following command:
apt-get install scala -y
Once the Scala is installed, verify the Scala installation using the following command:
scala -version
You should get the following output:
Scala code runner version 2.11.12 -- Copyright 2002-2017, LAMP/EPFL
Step 3 – Install Apache Spark
First, you will need to download the latest version of Apache Spark from its official website. You can download it with the following command:
wget https://downloads.apache.org/spark/spark-3.5.0/spark-3.5.0-bin-hadoop3-scala2.13.tgz
Once the download is completed, extract the downloaded file with the following command:
tar -xvzf spark-3.5.0-bin-hadoop3-scala2.13.tgz
Next, move the extracted directory to /opt:
mv spark-3.5.0-bin-hadoop3-scala2.13 /opt/spark
Next, you will need to define an environment variable to run Spark.
You can define it inside the ~/.bashrc file:
nano ~/.bashrc
Add the following line:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Save and close the file, then activate the environment variable with the following command:
source ~/.bashrc
Step 4 – Start Apache Spark Cluster
At this point, Apache spark is installed. You can now start the Apache Spark using the following command:
start-master.sh
You should get the following output:
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-debian10.out
By default, Apache Spark listens on port 8080. You can check it with the following command:
ss -tunelp | grep 8080
You should get the following output:
tcp LISTEN 0 1 *:8080 *:* users:(("java",pid=5931,fd=302)) ino:24026 sk:9 v6only:0 <->
Step 5 – Start Apache Spark Worker Process
Next, start the Apache Spark worker process with the following command:
start-worker.sh spark://debian10:7077
You should get the following output:
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-debian10.out
Step 6 – Access Apache Spark
You can now access the Apache Spark web interface using the URL http://your-server-ip:8080. You should see the Apache Spark dashboard on the following screen:
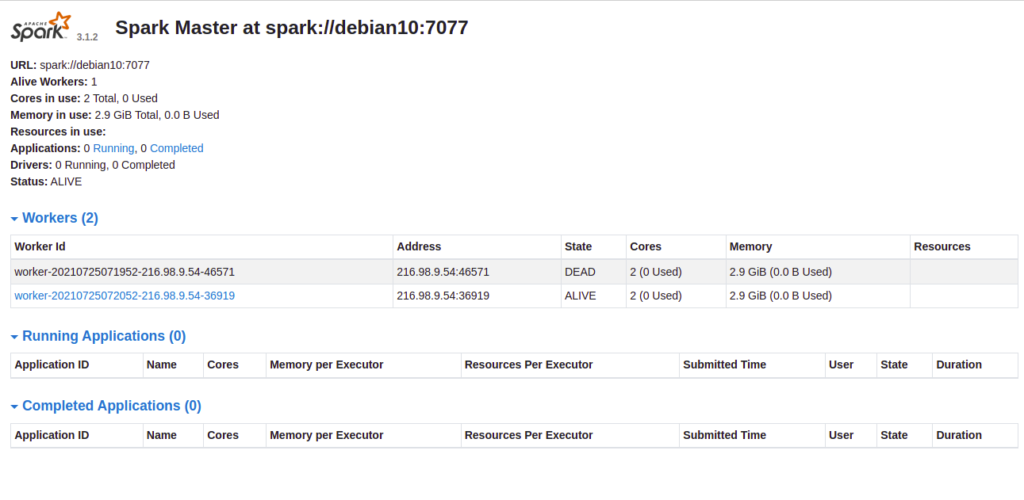
Step 7 – Access Apache Spark Shell
Apache Spark also provides a command-line interface to manage Apache Spark. You can access it using the following command:
spark-shell
Once you are connected, you should get the following shell:
Spark context Web UI available at http://debian10:4040
Spark context available as 'sc' (master = local[*], app id = local-1627197681924).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.11)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
If you want to stop the Apache Spark cluster, run the following command:
stop-master.sh
To stop the Apache Spark worker, run the following command:
stop-worker.sh
Conclusion
Congratulations! You have successfully installed and configured Apache Spark on Debian 10. This guide will help you to perform basic tests before you start configuring a Spark cluster and performing advanced actions. Try it on your dedicated server today!