Prerequisites
- Ubuntu 22.04: I will be using Ubuntu 22.04 throughout this demo. You can install your Ubuntu server in under 30 seconds from the Atlantic.Net Cloud Platform Console.
- Basic Python Knowledge: Familiarity with Python and virtual environments is helpful.
- Zilliz Account – You will need a Zilliz Account. They offer a free tier.
Part 1 – Create a Zilliz Free Account & Create Zilliz Cluster
While you can’t install the Zilliz Cloud service directly onto an Atlantic.Net Cloud Server, you can use your server to connect to and interact with Zilliz Cloud.
Here’s how you can set things up:
Step 1 – Connect to Zilliz Cloud
Create a Zilliz Cloud Account:
- Sign up for an account on Zilliz Cloud (zilliz.com/cloud).
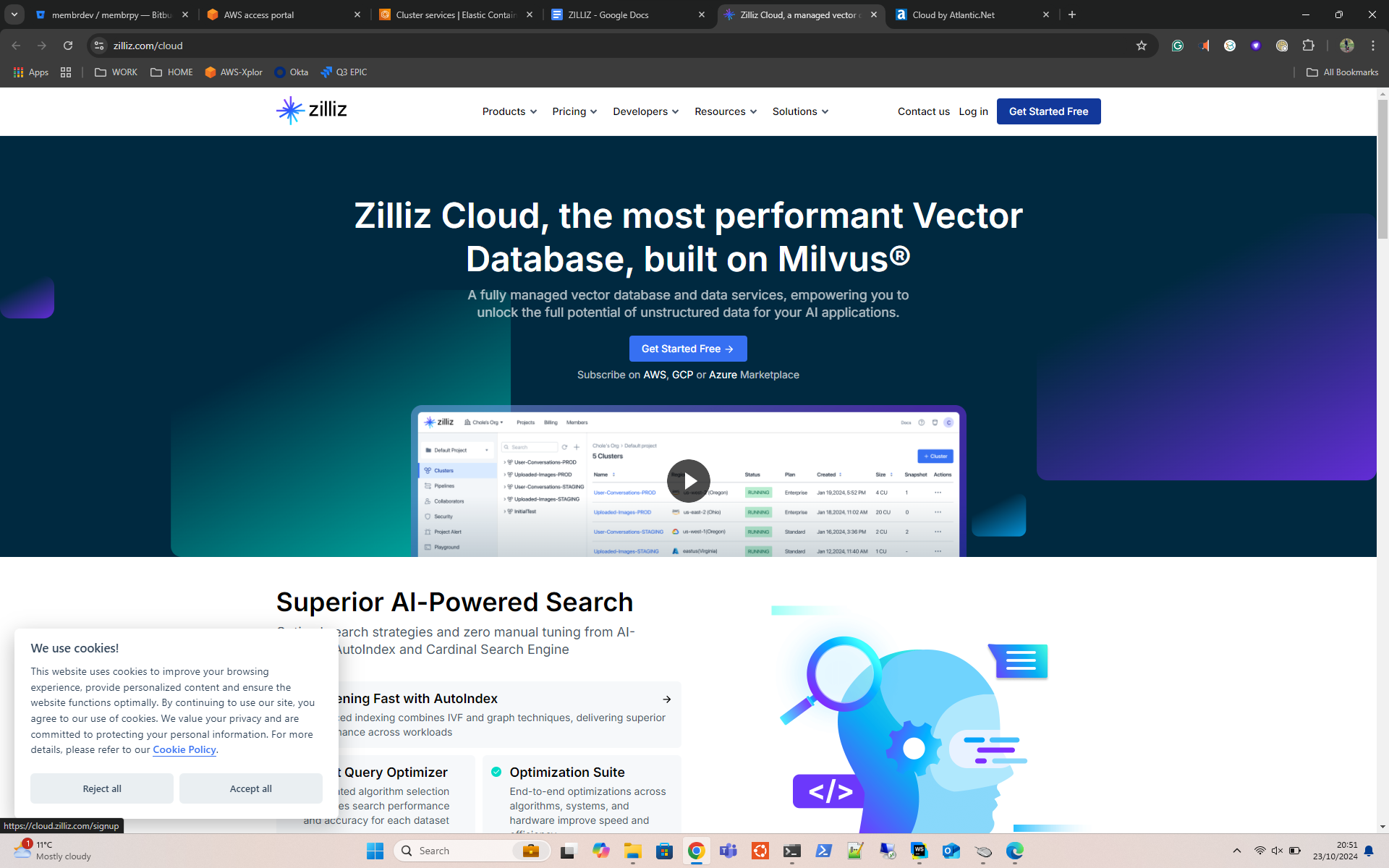
- Use the Sign-Up pages to create an account as per the below image. You can also use your existing GitHub or Google accounts for added simplicity.
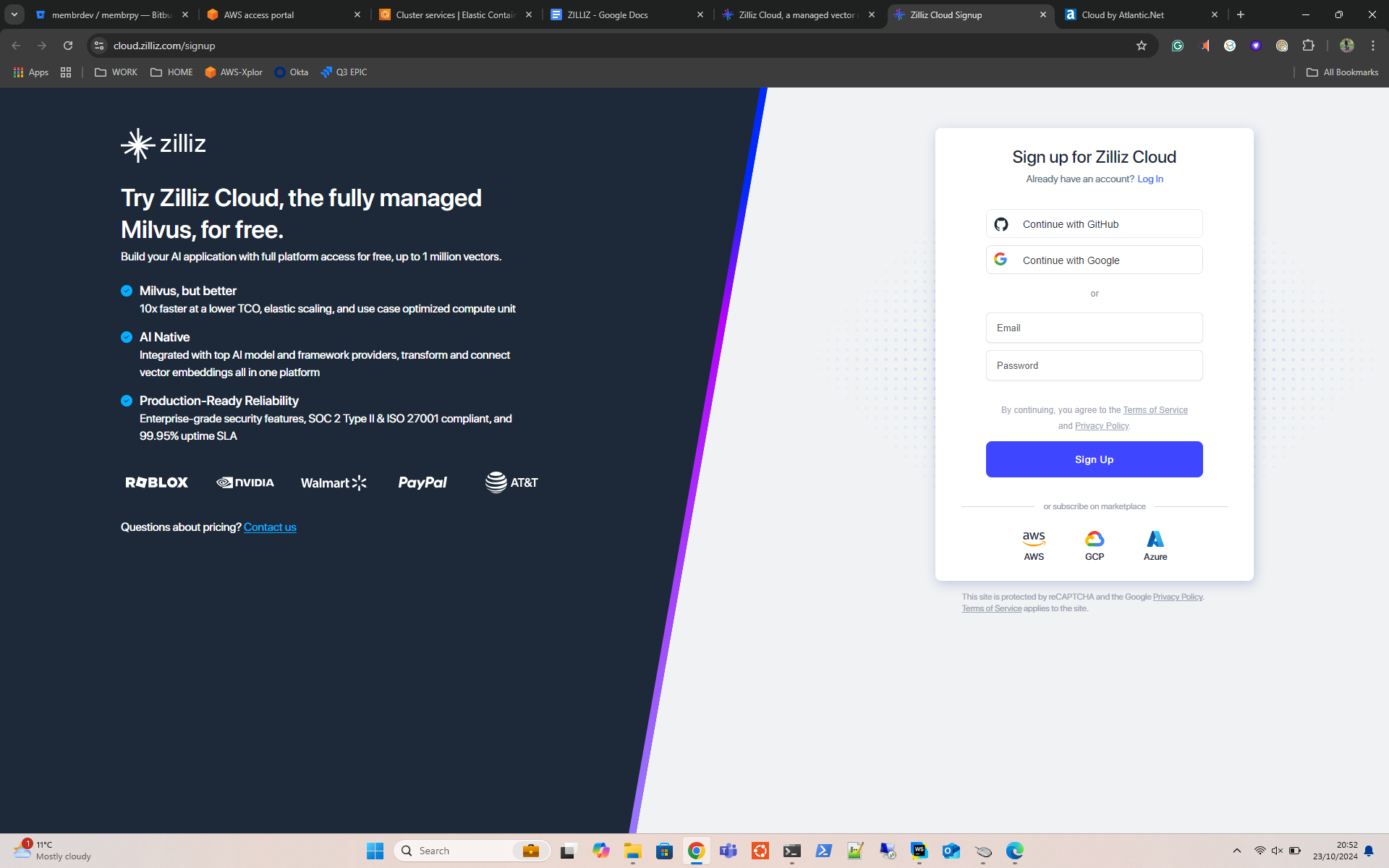
Step 2 – Create Zilliz Cluster
We can now create a Zillz cluster in the GUI.
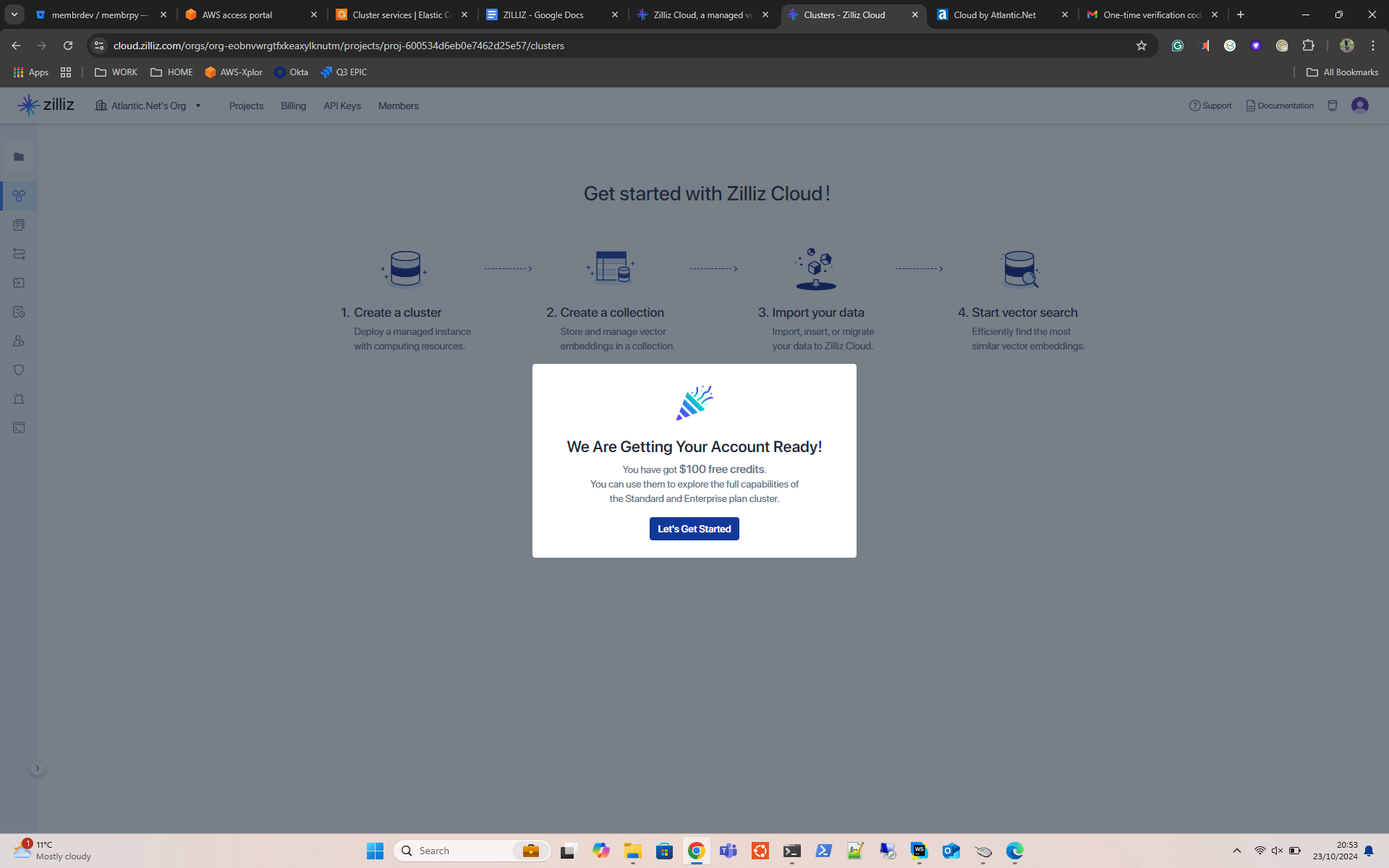
- From the Get Started Page on Zilliz, click on New Cluster.
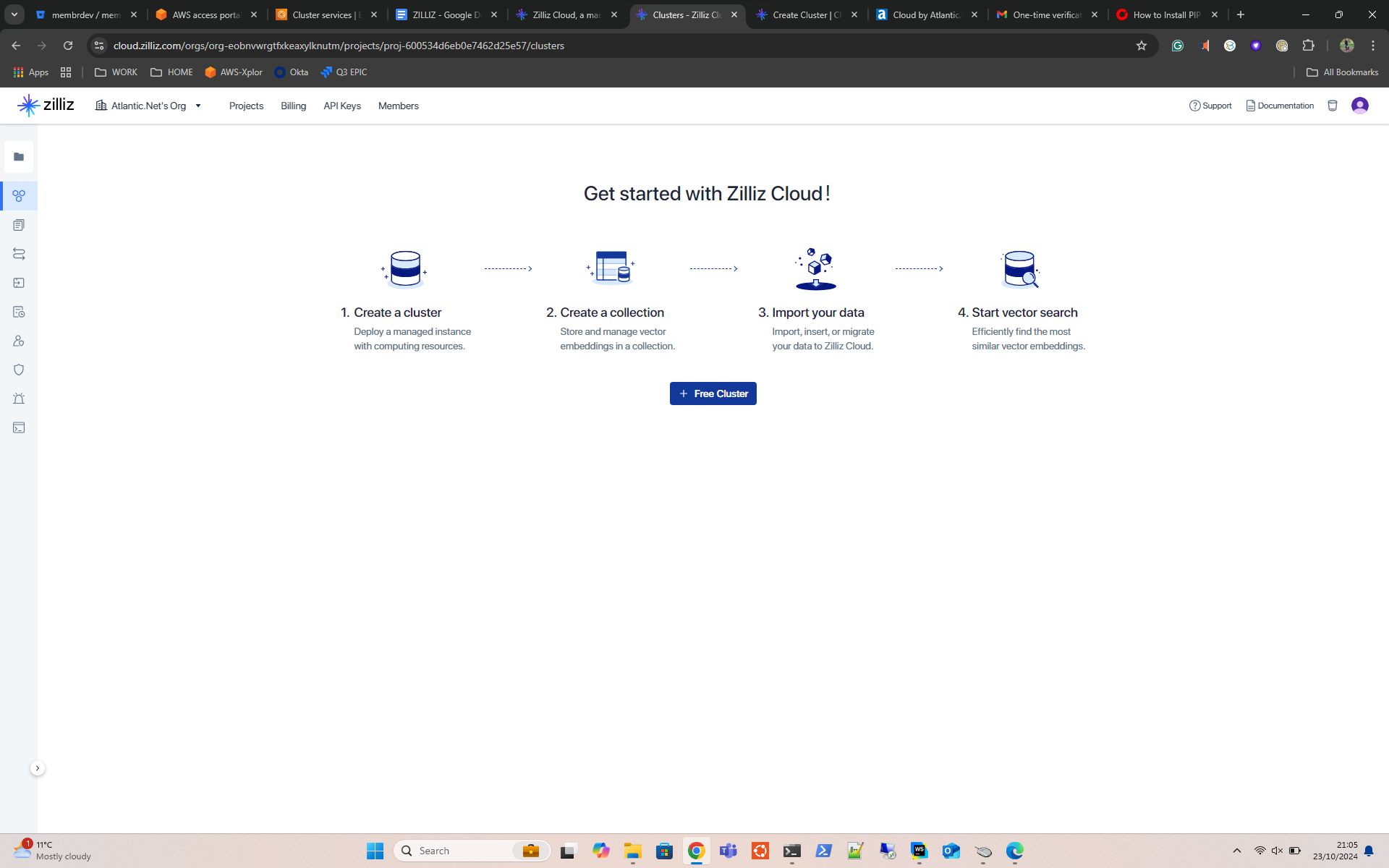
- Select the Free Tier. This will only give you the option to deploy Zilliz in GCP.
- Check the details and hit Create.
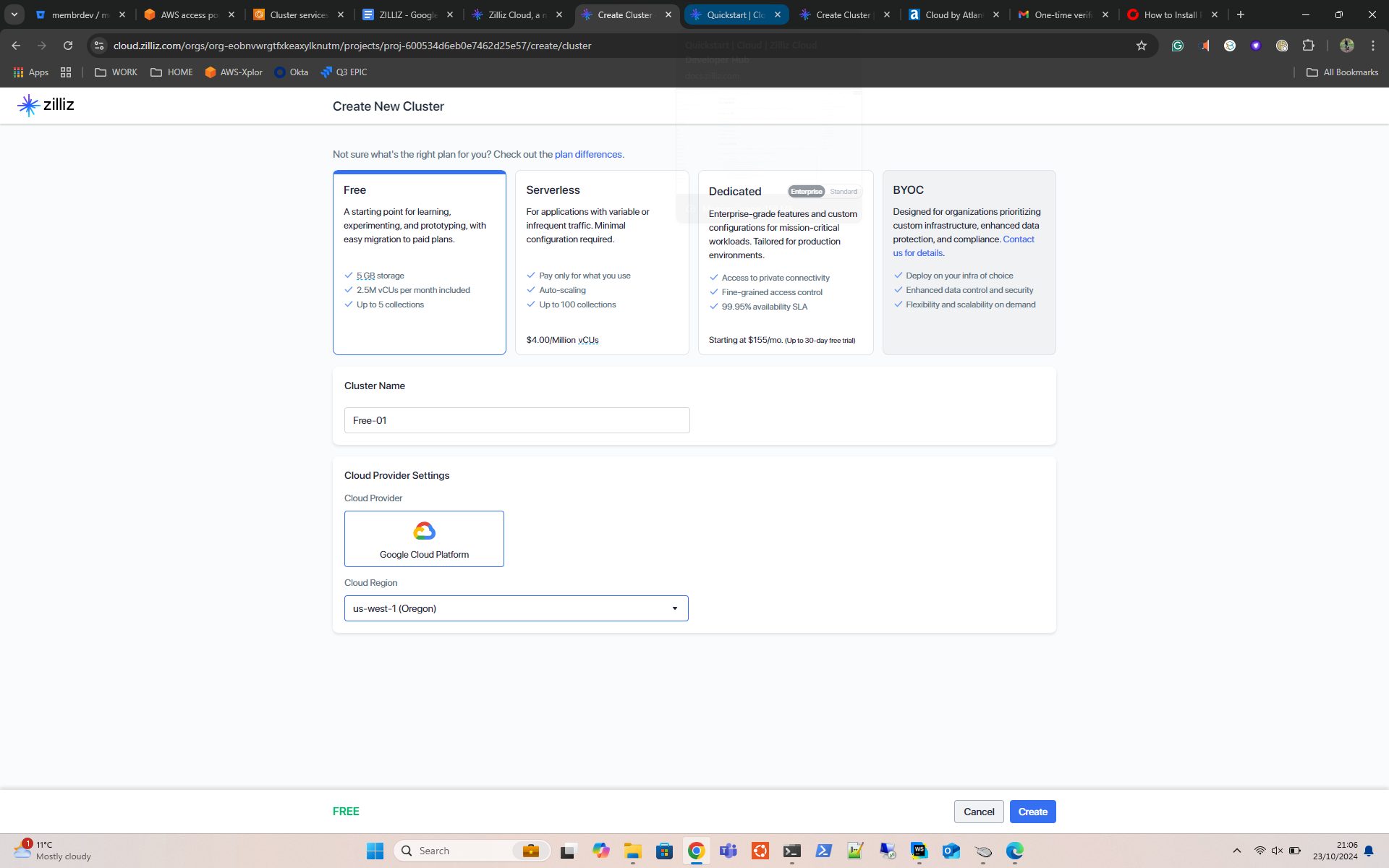
- Wait for the Cluster to build and move on to part 2. You may want to make a note of your endpoint ID and API key at this point. You can view these later, so it’s not a disaster if you forget.
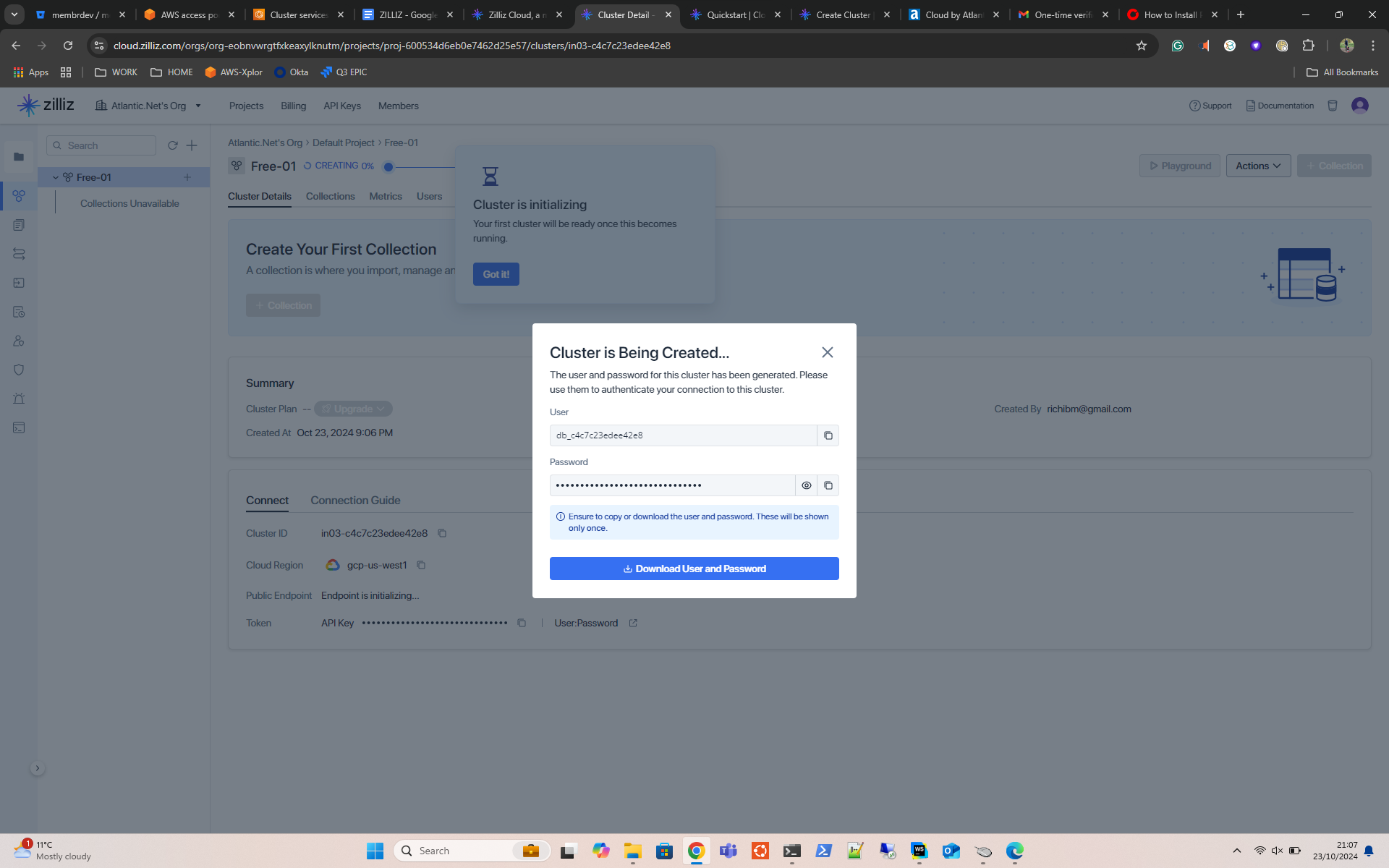
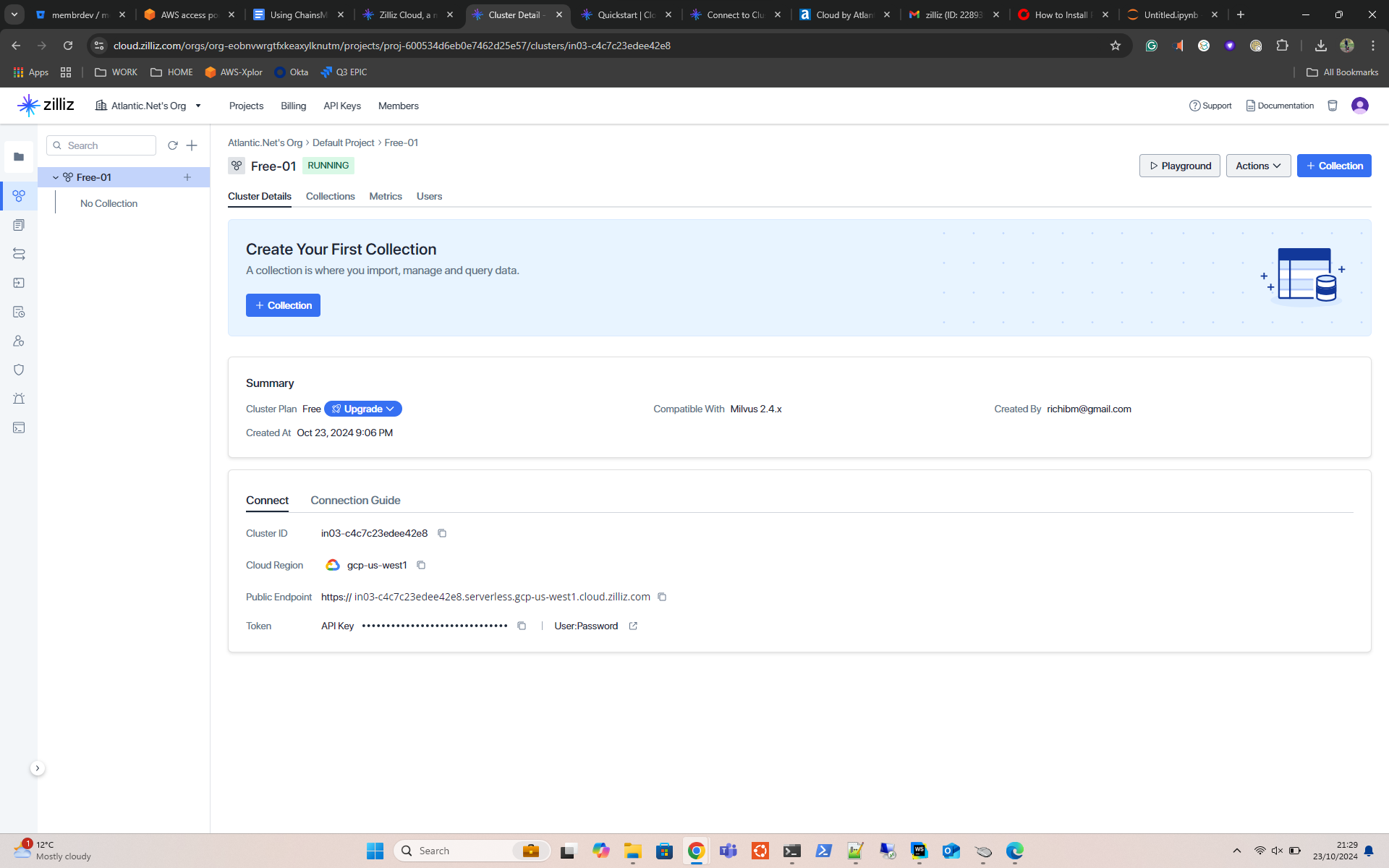
Part 2 – Install Python & Jupyter Notebooks
There are several ways you can use Zilliz, but you must use it with an SDK. This procedure will follow the steps to use Python, but please be aware that Zilliz supports Java and NodeJS if that is your preferred SDK.
Step 1 – Install Python
Jupyter Lab requires Python. You can install it using the following commands:
apt update -y apt install python3 python3-pip -y
Note: You may be prompted to restart services after installation. Just click <ok>.
Next, install the Python virtual environment package.
pip install -U virtualenv
Step 2 – Install Jupyter Lab
Now, install Jupyter Lab using the pip command.
pip3 install jupyterlab
This command installs Jupyter Lab and its dependencies. Next, edit the .bashrc file.
nano ~/.bashrc
Define your Jupyter Lab path as shown below; simply add it to the bottom of the file:
export PATH=$PATH:~/.local/bin/
Reload the changes using the following command.
source ~/.bashrc
Next, test run the Jupyter Lab locally using the following command to make sure everything starts.
jupyter lab --allow-root --ip=0.0.0.0 --no-browser
Check the output to make sure there are no errors. Upon success you will see the following output.
[C 2023-12-05 15:09:31.378 ServerApp] To access the server, open this file in a browser: http://ubuntu:8888/lab?token=aa67d76764b56c5558d876e56709be27446 http://127.0.0.1:8888/lab?token=aa67d76764b56c5558d876e56709be27446
Press the CTRL+C to stop the server.
Step 3 – Configure Jupyter Lab
By default, Jupyter Lab doesn’t require a password to access the web interface. To secure Jupyter Lab, generate the Jupyter Lab configuration using the following command.
jupyter-lab --generate-config
Output.
Writing default config to: /root/.jupyter/jupyter_lab_config.py
Next, set the Jupyter Lab password.
jupyter-lab password
Set your password as shown below:
Enter password: Verify password: [JupyterPasswordApp] Wrote hashed password to /root/.jupyter/jupyter_server_config.json
You can verify your hashed password using the following command.
cat /root/.jupyter/jupyter_server_config.json
Output.
{
"IdentityProvider": {
"hashed_password": "argon2:$argon2id$v=19$m=10240,t=10,p=8$zf0ZE2UkNLJK39l8dfdgHA$0qIAAnKiX1EgzFBbo4yp8TgX/G5GrEsV29yjHVUDHiQ"
}
}
Note this information, as you will need to add it to your config.
Next, edit the Jupyter Lab configuration file.
nano /root/.jupyter/jupyter_lab_config.py
Define your server IP, hashed password, and other configurations as shown below:
c.ServerApp.ip = 'your-server-ip' c.ServerApp.open_browser = False c.ServerApp.password = 'argon2:$argon2id$v=19$m=10240,t=10,p=8$zf0ZE2UkNLJK39l8dfdgHA$0qIAAnKiX1EgzFBbo4yp8TgX/G5GrEsV29yjHVUDHiQ' c.ServerApp.port = 8888
Make sure you format the file exactly as above. For example, the port number is not in brackets, and the False boolean must have a capital F.
Save and close the file when you are done.
Step 4 – Create a Systemctl Service File
Next, create a systemd service file to manage Jupyter Lab.
nano /etc/systemd/system/jupyter-lab.service
Add the following configuration:
[Service] Type=simple PIDFile=/run/jupyter.pid WorkingDirectory=/root/ ExecStart=/usr/local/bin/jupyter lab --config=/root/.jupyter/jupyter_lab_config.py --allow-root User=root Group=root Restart=always RestartSec=10 [Install] WantedBy=multi-user.target
Save and close the file, then reload the systemd daemon.
systemctl daemon-reload
Next, start the Jupyter Lab service using the following command.
systemctl start jupyter-lab
You can now check the status of the Jupyter Lab service using the following command.
systemctl status jupyter-lab
Jupyter Lab is now started and listening on port 8888. You can verify it with the following command.
ss -antpl | grep jupyter
Output.
LISTEN 0 128 104.219.55.40:8888 0.0.0.0:* users:((“jupyter-lab”,pid=156299,fd=6))
Step 5 – Access Jupyter Lab
Now, open your web browser and access the Jupyter Lab web interface using the URL http://your-server-ip:8888. You will see Jupyter Lab on the following screen.
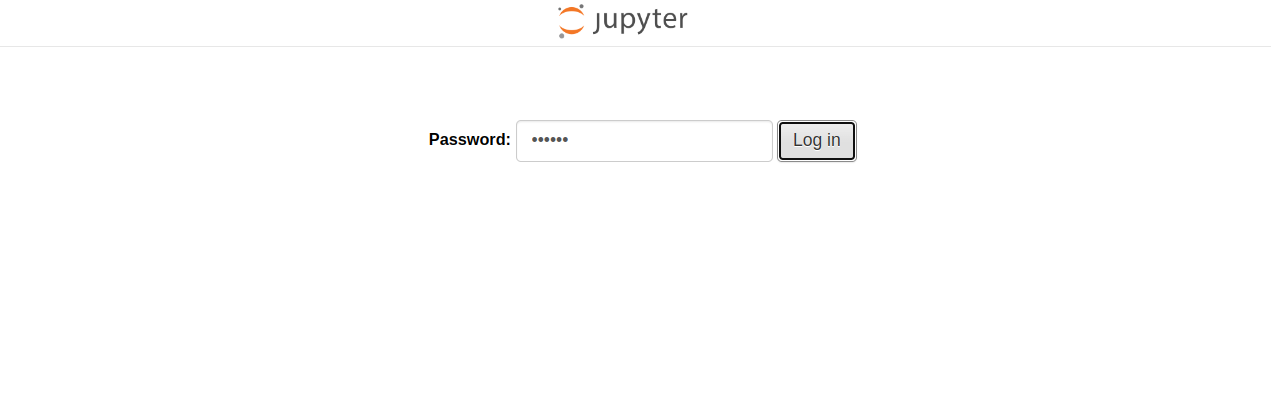
Provide the password you set during the installation and click on Log in. You will see the Jupyter Lab dashboard on the following screen:
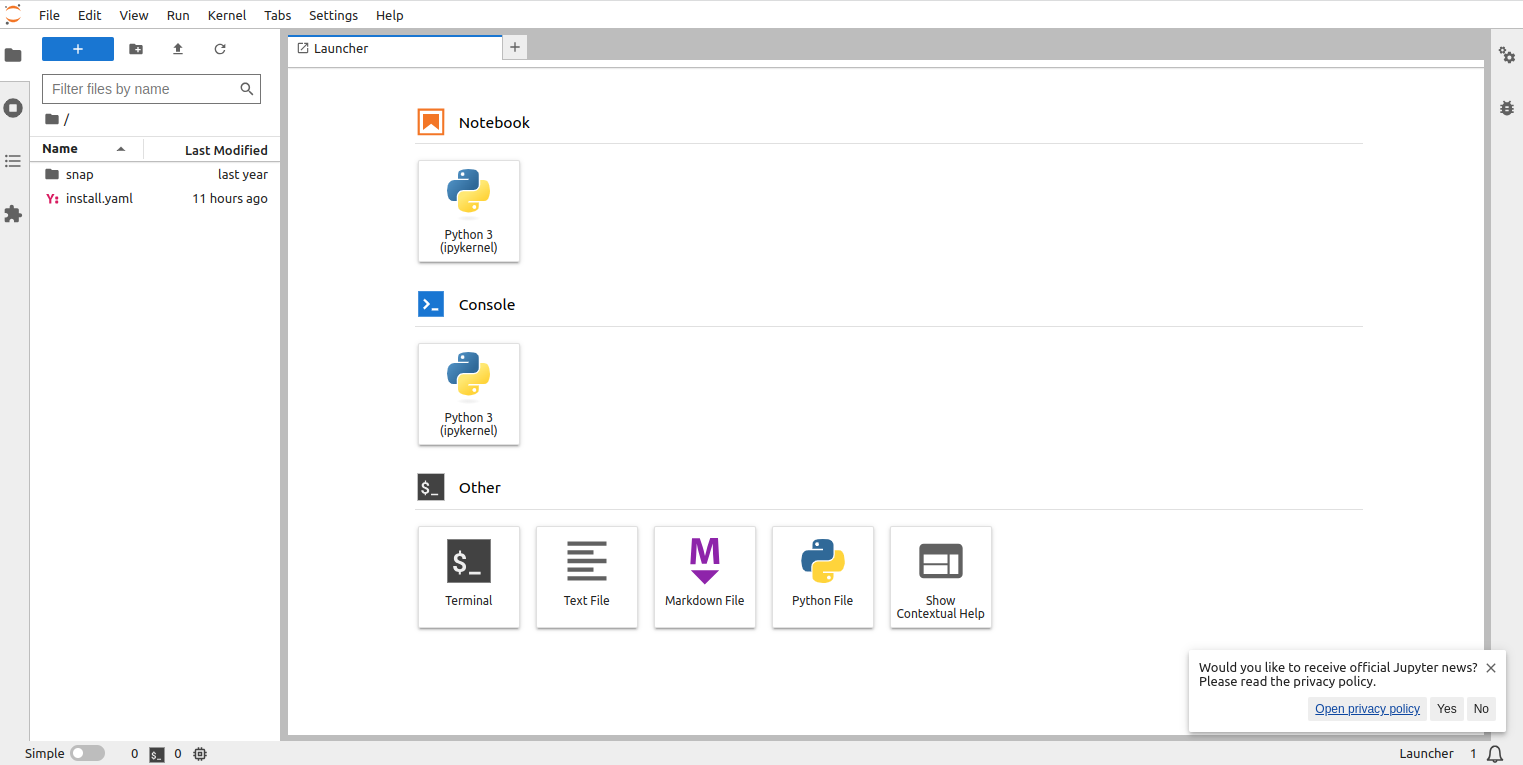
Step 6 – Start the Python3 Notebook
You can now start the Python 3 Notebook and move on to Part 3.
Part 3 – Install and Configure Zilliz Cluster
Now go back to your VPS terminal. We will install Zilliz and configure the cluster.
Step 1 – Install Pymilvus
- Install PyMilvus compatible with Milvus v2.4.x
python -m pip install pymilvus==2.4.4
- Upgrade PyMilvus to the newest version.
python -m pip install --upgrade pymilvus
- Verify installation success.
python -m pip list | grep pymilvus
Step 2 – Connect to Cluster
Now let’s connect to the cluster.
Go back to your Jupyter notebook and execute the following code. Make sure you update the following parameters:
CLUSTER_ENDPOINT=”YOUR_CLUSTER_ENDPOINT” # Set your cluster endpoint
TOKEN=”YOUR_CLUSTER_TOKEN” # Set your token
# Connect using a MilvusClient object from pymilvus import MilvusClient CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT" # Set your cluster endpoint TOKEN="YOUR_CLUSTER_TOKEN" # Set your token
Step 3 – Initialize the Zilliz Cluster
- Now initialize the cluster.
# Initialize a MilvusClient instance # Replace uri and token with your own client = MilvusClient( uri=CLUSTER_ENDPOINT, # Cluster endpoint obtained from the console token=TOKEN # API key or a colon-separated cluster username and password )
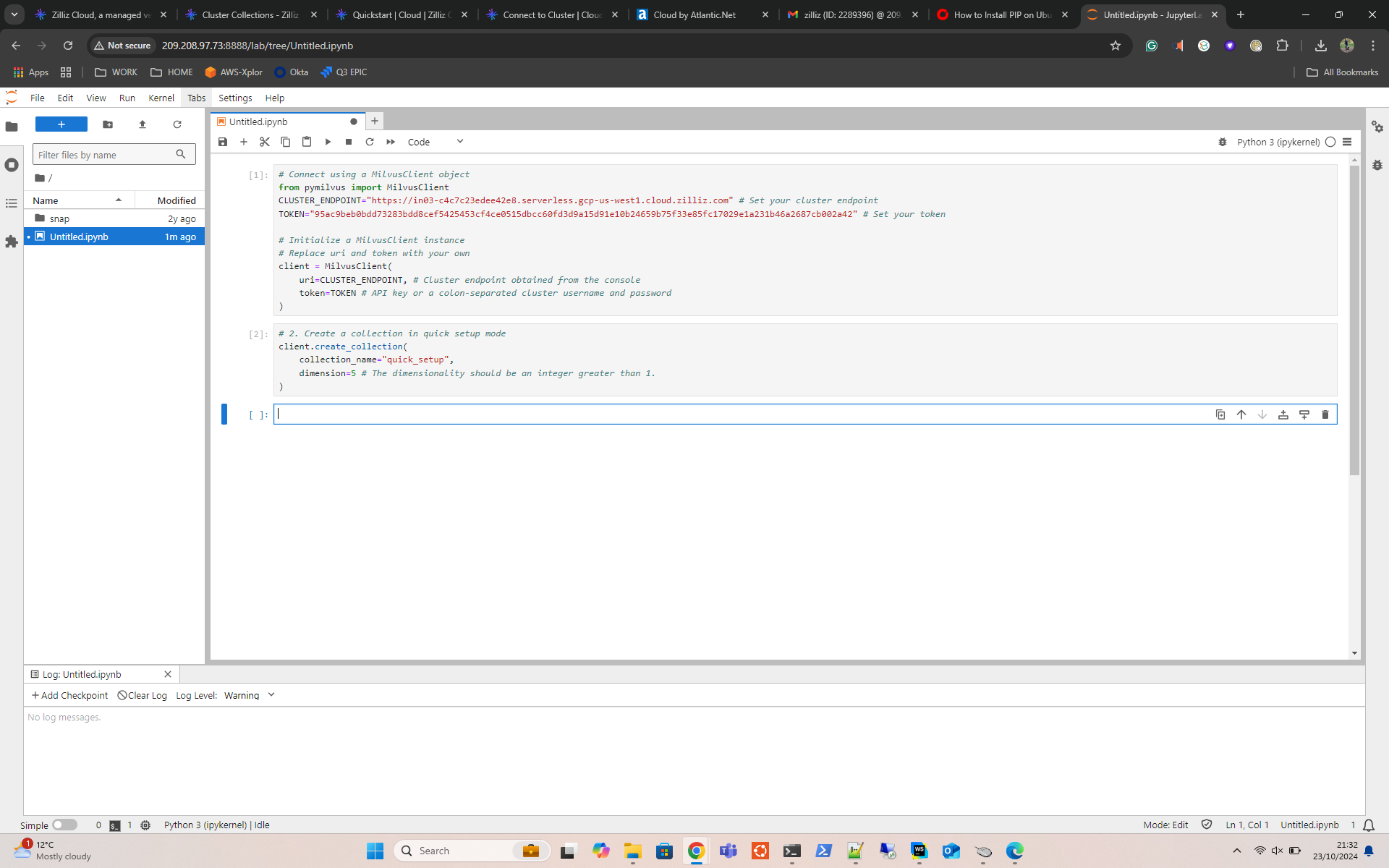
Step 4 – Create a Collection
Let’s create a collection.
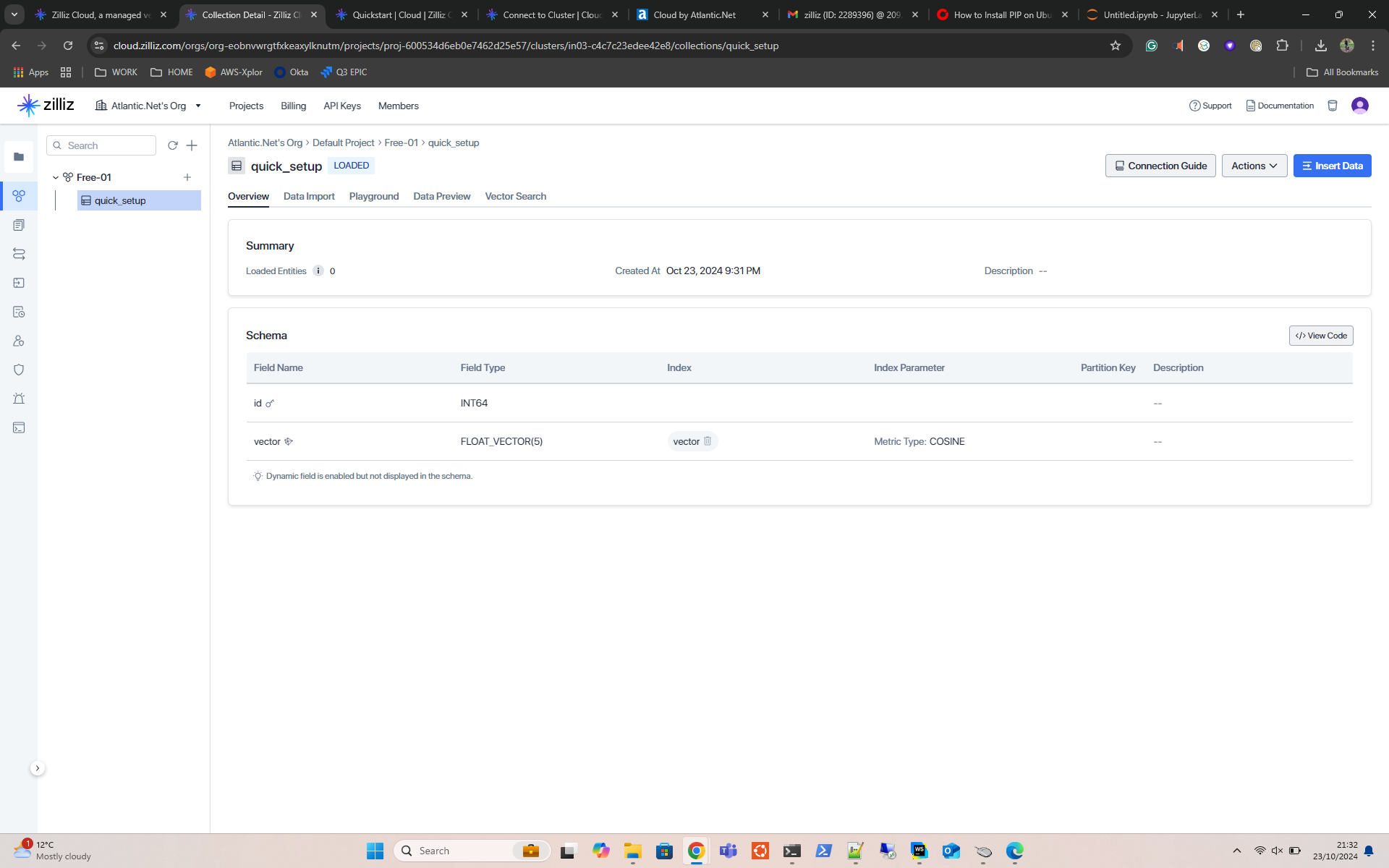
In Zilliz Cloud, a collection is like a table in a traditional database, but it’s specifically designed to store and manage vector data along with its associated metadata.
client.create_collection( collection_name="quick_setup", dimension=5 # The dimensionality should be an integer greater than 1. )
Step 5 – Insert Some Data
Now let’s populate the Vector DB with some dummy data for testing.
Note: The official Zilliz documentation provides this data.
- Run the following in your Jupyter notebook:
# 4. Insert data into the collection
# 4.1. Prepare data
data=[
{"id": 0, "vector": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], "color": "pink_8682"},
{"id": 1, "vector": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104], "color": "red_7025"},
{"id": 2, "vector": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592], "color": "orange_6781"},
{"id": 3, "vector": [0.3172005263489739, 0.9719044792798428, -0.36981146090600725, -0.4860894583077995, 0.95791889146345], "color": "pink_9298"},
{"id": 4, "vector": [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106], "color": "red_4794"},
{"id": 5, "vector": [0.985825131989184, -0.8144651566660419, 0.6299267002202009, 0.1206906911183383, -0.1446277761879955], "color": "yellow_4222"},
{"id": 6, "vector": [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987], "color": "red_9392"},
{"id": 7, "vector": [-0.33445148015177995, -0.2567135004164067, 0.8987539745369246, 0.9402995886420709, 0.5378064918413052], "color": "grey_8510"},
{"id": 8, "vector": [0.39524717779832685, 0.4000257286739164, -0.5890507376891594, -0.8650502298996872, -0.6140360785406336], "color": "white_9381"},
{"id": 9, "vector": [0.5718280481994695, 0.24070317428066512, -0.3737913482606834, -0.06726932177492717, -0.6980531615588608], "color": "purple_4976"}
]# 4.2. Insert data
res = client.insert(
collection_name="quick_setup",
data=data
)
print(res)
# Output
#
# {
# "insert_count": 10,
# "ids": [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# }
- Let’s insert more data.
import time
# 5. Insert more data into the collection
# 5.1. Prepare data
colors = ["green", "blue", "yellow", "red", "black", "white", "purple", "pink", "orange", "brown", "grey"]
data = [ {
"id": i,
"vector": [ random.uniform(-1, 1) for _ in range(5) ],
"color": f"{random.choice(colors)}_{str(random.randint(1000, 9999))}"
} for i in range(1000) ]
# 5.2. Insert data
res = client.insert(
collection_name="quick_setup",
data=data[10:]
)
print(res)
# Output
#
# {
# "insert_count": 990
# }
# Wait for a while
time.sleep(5)
Step 6 – Perform a Vector Search
Now let’s query the data using a vector search.
Single Vector Search
# 6.1. Prepare query vectors query_vectors = [ [0.041732933, 0.013779674, -0.027564144, -0.013061441, 0.009748648] ]# 6.2. Start search res = client.search( collection_name="quick_setup", # target collection data=query_vectors, # query vectors limit=3, # number of returned entities ) print(res)
You should see output like this:
# Output
#
# [
# [
# {
# "id": 551,
# "distance": 0.08821295201778412,
# "entity": {}
# },
# {
# "id": 296,
# "distance": 0.0800950899720192,
# "entity": {}
# },
# {
# "id": 43,
# "distance": 0.07794742286205292,
# "entity": {}
# }
# ]
# ]
Bulk-Vector Search
# 7. Search with multiple vectors # 7.1. Prepare query vectors query_vectors = [ [0.041732933, 0.013779674, -0.027564144, -0.013061441, 0.009748648], [0.0039737443, 0.003020432, -0.0006188639, 0.03913546, -0.00089768134] ]# 7.2. Start search res = client.search( collection_name="quick_setup", data=query_vectors, limit=3, ) print(res)
You should see output like this:
# Output
#
# [
# [
# {
# "id": 551,
# "distance": 0.08821295201778412,
# "entity": {}
# },
# {
# "id": 296,
# "distance": 0.0800950899720192,
# "entity": {}
# },
# {
# "id": 43,
# "distance": 0.07794742286205292,
# "entity": {}
# }
# ],
# [
# {
# "id": 730,
# "distance": 0.04431751370429993,
# "entity": {}
# },
# {
# "id": 333,
# "distance": 0.04231833666563034,
# "entity": {}
# },
# {
# "id": 232,
# "distance": 0.04221535101532936,
# "entity": {}
# }
# ]
# ]
That’s it! You are now ready to start using Zilliz Vector Databases with your Atlantic.Net hosted cloud server. Remember, you don’t have to use Python, Zilliz natively supports Java and NodeJS if that’s your preference.
* This post is for informational purposes only and does not constitute professional, legal, financial, or technical advice. Each situation is unique and may require guidance from a qualified professional.
Readers should conduct their own due diligence before making any decisions.